Abstract
We wanted to create a novel application that would recommend songs and music playlists based on user prompts. While Spotify came out with a similar feature recently, we wanted to create an application that reads into the user's prompt more deeply. QWEN-Audio was used to decipher the songs in our datasets and extract musical features. We then used the Gemini API to interpret the human prompts to extract similar features from that, and we also gathered some feedback to help in training the model. Currently, a working demo is available (above) that can take a user prompt and return a song recommendation based on that prompt. Our results show that our model is capable of creating playlists that are somewhat consistent with the user's intent, though it seems that, out of the people surveyed, Spotify's reccomendations were preferred.
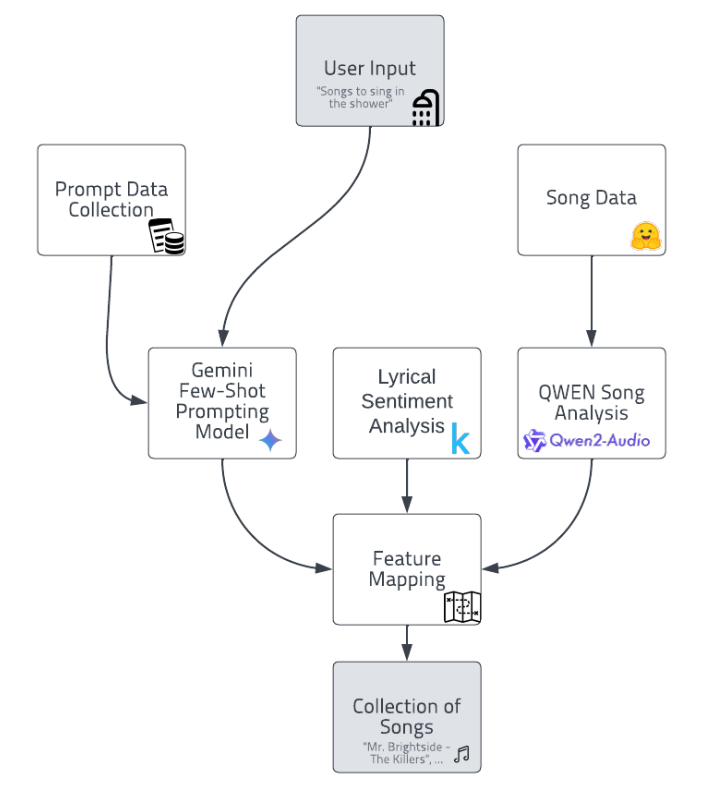
A basic representation of how our application will prosses data to give results.
Introduction / Background / Motivation
What we are trying to do
We want to create an application that would recommend songs and music playlists based on user prompts, wanting to create a more personalized and tailored experience for the user. We also wanted to discover what kind of music our application thinks very abstract prompts would sound like. For example, what would a song sound like if it was based on the prompt "a song that sounds like a sunset"? Our goal is to create something that is not affected by the user's listening history and is more based on the prompt itself while being able to handle more abstract prompts and hopefully return sensible songs.
How is it done today, and what are the limits of current practice?
Spotify has a new feature that recommends songs and playlists based on user listening history and song titles. However, the recommendations that Spotify gives are not very in-depth, and a lot of the recommendations are based on the user's listening history and song titles. Because of this, the songs they provide are not going to "catch the vibe" as it were, of the prompt given if the prompt is too abstract. There have also been plenty of studies looking into music recommendation systems, but there are still a few gaps in the research. For example, there is not much work on handling content-based prompts. Similarly, the integration of lyrical sentiment analysis with audio feature analysis has not been fully explored.
Obviously, with very abstract prompts it is extremely hard if not impossible to say whether or not a song is a good recommendation. Thus, there is a limit as to what can be expected from a music recommendation system. Furthermore, music is a very subjective medium, and because of this people will not like the songs that are recommended to them, while others may. It seems highly unlikely that we will see a music recommendation system that can perfectly predict what a user will like and wants in our lifetime. Lastly, there are an absurd number of songs within the human music library making it very difficult to create a model that can handle that much data.
Why should you care?
If we succeed, we will have created a music recommendation system that can handle abstract prompts and return sensible song suggestions. This could help people discover new music that they would not have found otherwise, along with aiding people to create playlists for moments in their lives with more ease. Our application will hopefully be able to capture more complex and metaphorical ideas than current music recommendation systems, and thus be able to recommend songs that are more in line with the user's intent. This will open up new possibilities for how people listen to music, allowing unfamiliar songs and artists to be discovered based on emotions and environment rather than just listening history.
Approach
What did you do exactly? How did you solve the problem? Why did you think it would be successful? Is anything new in your approach?
Our application was created with a simple enough pipeline in mind. First, we take the prompt given by the user and use a model to derive musical qualities and descriptors from it. Then we take the parsed descriptors and map them onto both audio a lyrical data using a separate model which extracts similar qualities and descriptors from the music dataset. We currently have two options for this, either using human feedback to train the model or using an LLM to output scores based on the human data. The LLM we are currently looking at is Gemini, which is capable of parsing features such as acousticness, danceability, etc. from the prompt given. Below is a diagram showing how this process works.

We thought this would be successful as integrating both lyrical and audio features would give us a more complete picture of the music, and thus a better recommendation. We did this initially using a MU-LLaMA (Music Understanding Large Language Model) model. Below is a diagram showing how this process works.
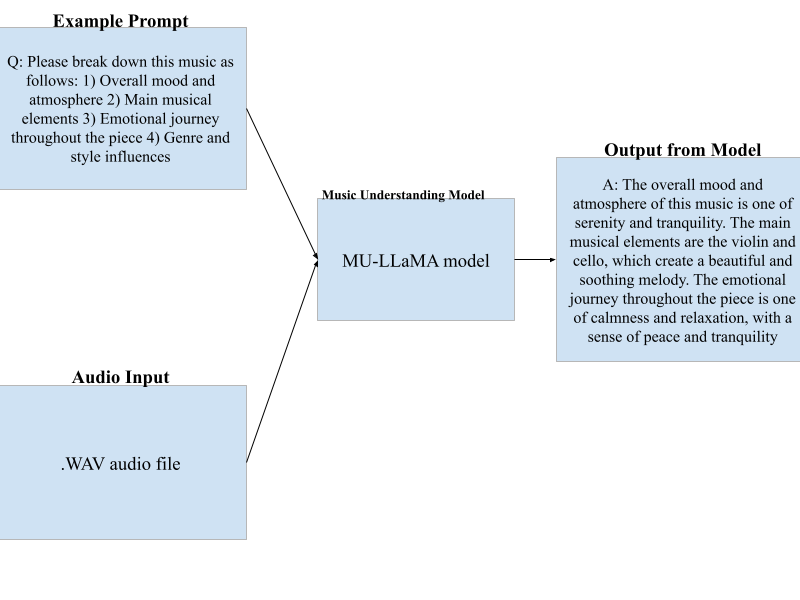
Our inital idea was to use MU-LLaMA to do the audio analysis. MU-LLaMA is a tool that can be used to extract musical features from audio files (specifically .wav files), while also being able to analyze lyrics in songs. The model works by feeding it an input .wav file and giving it a prompt asking for audio analysis, as shown in the diagram. As for handling abstract prompts, by parsing natural language into musical features, our application will be able to more readily understand the intent of the prompt.
However, we ended up using a differnt model for our audio analysis - QWEN-Audio. A recent review of the Music Understanding Language Model space cited the QWEN-Audio Model as the current state-of-the-art across most music understanding tasks. Simply put, QWEN was anecdotally more convenient to use, and more promising than MU-LLaMA. In combination with its ready availability, this made it our choice for the direct audio analysis portion of our pipeline. The QWEN-Audio Model analyzes various formats of audio files and accommodates natural language prompting and question-answering regarding the piece’s analysis. Our pipeline compiles a preprocessed library of song descriptions by analyzing musical audio with QWEN, and prompting it for a list of descriptors that capture the most distinctive and important characteristics of the piece, including genre, mood, and standout musical elements. The way in which QWEN was implmented in our pipeline was almost the exact same as what we had in mind for the MU-LLaMA model.
What problems did you anticipate? What problems did you encounter? Did the very first thing you tried work?
So far we have not encountered any major problems. One thing we did have to consider was how to train the model that handles the user input. We need a model to parse musical features from the prompt, and we have two options. First, we could use scores from human feedback to solely train the model, which would be more efficient given the smaller scope of this project. Otherwise, we could create an LLM such as Gemini to output scores based on the human data. This would be more flexible and allow for more complex prompts, but would also be more time-consuming. We have, of course, through the planning of this project worried about one main problem: music is subjective, and thus it is extremely hard to validate results. This being said, since we have our own metric scores along with Spotify's dataset, we should be able to come up with a reasonably effective metric. Using human feedback instead of the Spotify dataset is looking to be the way we will go at the moment. Either way, we will be trying both options in the hope of finding the best solution. For audio engineering, QWEN is extremely effective, however does have some limitations. For example, when given audio from popular meme culture, the model depicts a sad violin playing, given it has no cultural context. We have also tried to obtain song lyrics from datasets but found this to not be feasible, so web scraping seems to be our only option.
Preliminary Results
Before we had a working demo we had some preliminary results from various parts of our application. As for the audio parsing model, we had an experimental model using MU-LLaMA working that can obtain musical features from .wav files. (This is described in more detail in the Approach section.) For the human prompt, we had a working Gemini model that is capable of parsing features such as acoustics, danceability, etc. from the prompt given. This model is capable of handling abstract prompts, however, we were not able to verify the correctness of these results at the time. Lastly, a survey was conducted to gather human feedback on prompt features using the same tags as the Gemini model. These are the results discussed in the previous section about issues.
| Prompt | Number of responses | Acoustic Mean | Danceability Mean | Energy Mean | Instrumentalness Mean | Liveness Mean | Valence Mean |
|---|---|---|---|---|---|---|---|
| Songs for a sunny day | 5 | 6.2 | 8.4 | 8.4 | 3.8 | 3.8 | 9.6 |
| Music to study to | 5 | 7.0 | 2.2 | 4.0 | 8.4 | 2.2 | 5.2 |
| Songs for a party | 5 | 2.2 | 10.0 | 10.0 | 2.2 | 2.0 | 9.2 |
| Chill Music Before Bed | 5 | 7.8 | 3.2 | 2.0 | 6.4 | 3.0 | 4.4 |
| Workout playlist | 5 | 2.2 | 9.6 | 10.0 | 2.4 | 2.0 | 8.2 |
| Romantic Dinner Songs | 11 | 7.3 | 5.0 | 3.4 | 4.6 | 3.7 | 7.4 |
| Sad Love Songs | 11 | 7.3 | 2.0 | 2.5 | 4.5 | 2.9 | 1.1 |
| Winter Music | 11 | 6.5 | 4.3 | 5.3 | 5.7 | 3.7 | 6.5 |
| Songs for a rainy day | 11 | 7.2 | 3.5 | 3.0 | 6.0 | 4.9 | 3.5 |
| Jazz Classics | 11 | 7.6 | 7.7 | 7.4 | 8.9 | 6.9 | 6.4 |
| Backyard barbecue | 7 | 3.6 | 4.9 | 6.1 | 3.4 | 3.7 | 9.1 |
| Nostalgic hits | 7 | 3.9 | 7.6 | 7.7 | 3.2 | 2.3 | 8.0 |
| Fall songs | 7 | 6.9 | 3.3 | 4.3 | 5.9 | 4.1 | 4.1 |
| Late night driving | 7 | 5.3 | 5.3 | 6.0 | 5.4 | 2.3 | 5.4 |
| Good vibes pop | 7 | 2.7 | 8.6 | 8.1 | 2.9 | 2.6 | 9.7 |
| Pregame jams | 6 | 2.7 | 9.3 | 9.3 | 3.2 | 2.3 | 9.7 |
| Sleepy music | 6 | 8.0 | 1.7 | 1.7 | 7.0 | 2.0 | 5.3 |
| Spring hits | 6 | 5.8 | 6.3 | 7.0 | 3.7 | 5.5 | 7.7 |
| Calm focus playlist | 6 | 7.8 | 1.5 | 2.8 | 7.8 | 1.8 | 5.5 |
| Sleepless midnight | 6 | 5.3 | 4.7 | 4.7 | 4.3 | 4.3 | 4.0 |
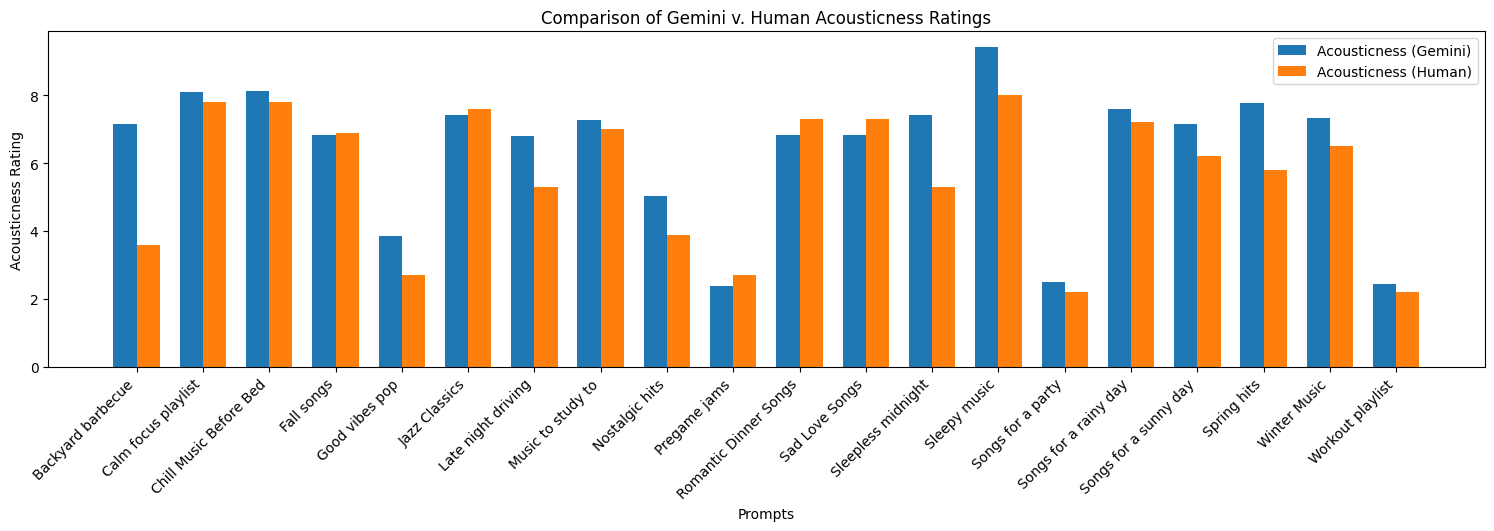
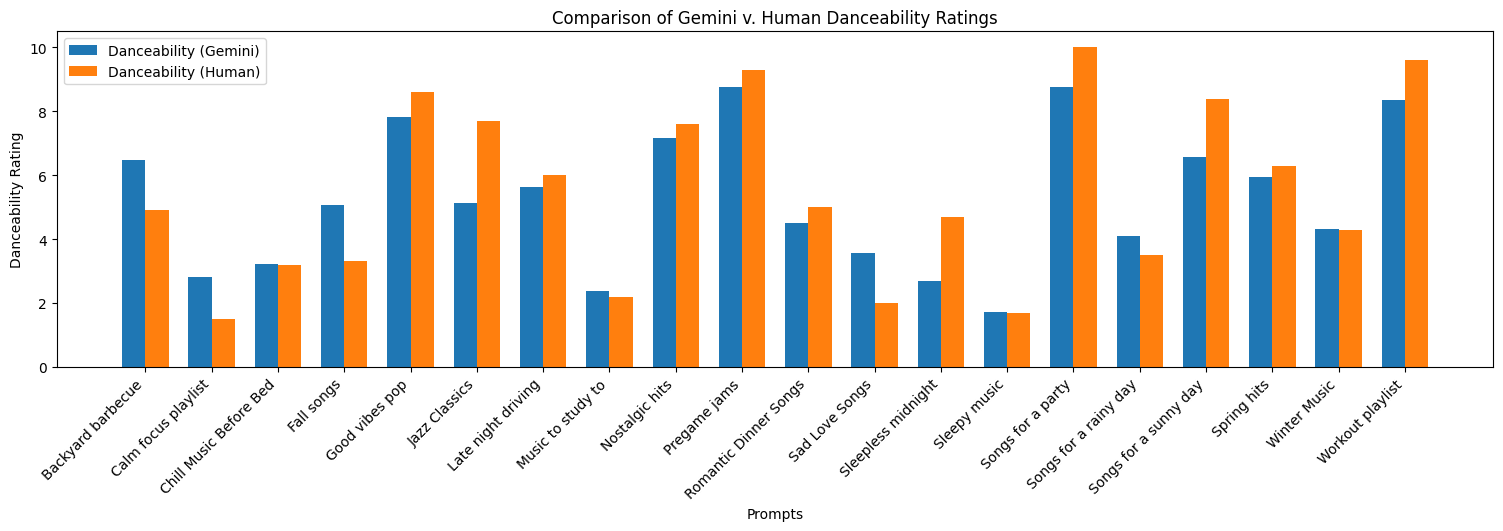
Here we have the comparisons from the peer responses and the Gemini Outputs.

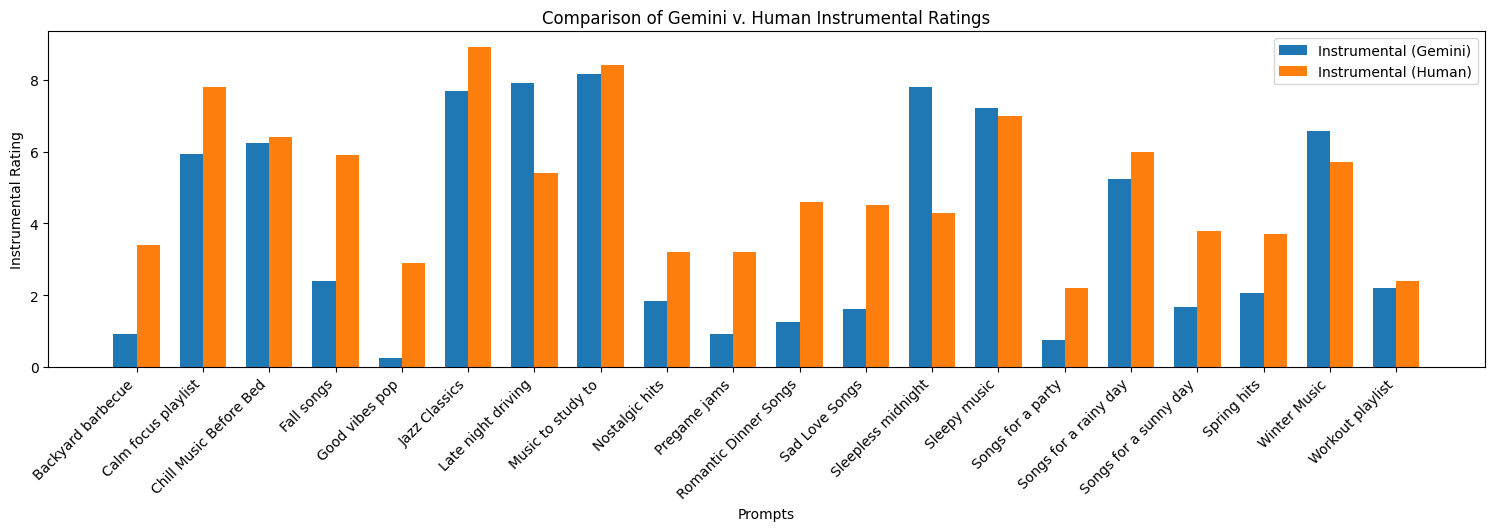
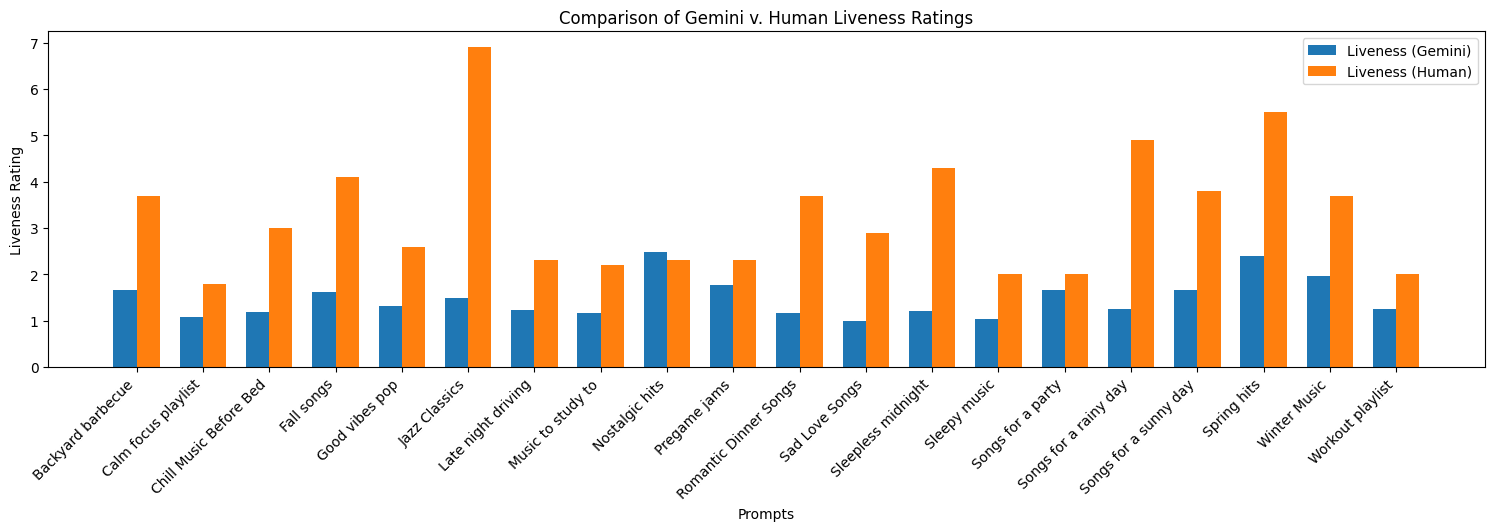
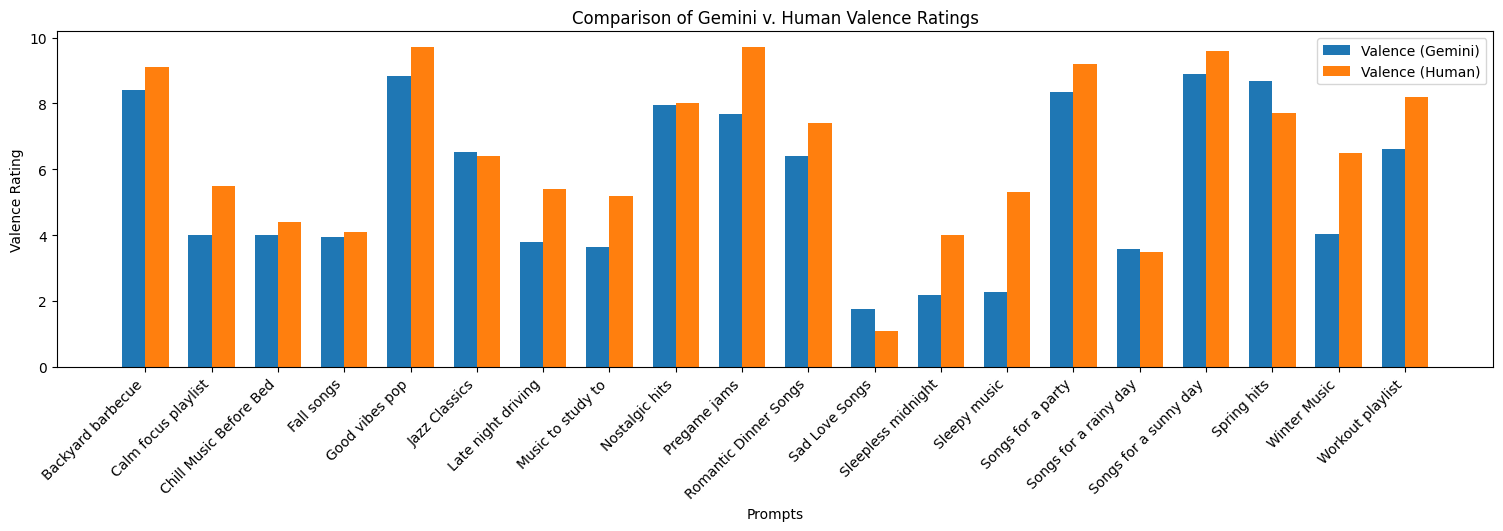
Final Results
The first point of success for our project was to deliver a working prototype of the system. As of 12/12/2024 a live demo is available linked from our project website. For members of our group and participants at our poster session, this demo provided a functional demonstration of our system and accommodated a wide variety of untested prompts for playlist curation.
In order to better objectify the degree to which our system performs its goal task, we needed to design a battery of evaluation metrics. Due to the subjective nature of our task, we looked to user feedback to quantify the system’s performance. A foundational component of our music recommendation pipeline is the decomposition of user prompts into a set of in-domain adjectives. The result of this step in the pipeline determines the musical descriptors that are used to search song descriptions generated by the QWEN audio LM, and therefore must be accurate in order to serve fitting recommendations. Therefore, this was the first component of our system we evaluated via human feedback. To get useful feedback on prompt descriptions, we designed a survey to see how users would agree to the adjectives that the model returned for the given prompt. To obtain these prompts, we first chose ones that had relatively straightforward ideas of what adjectives and songs could be derived from, and then as the list went down, the prompts got more abstract and nuanced, essentially trying to confuse the model. In total, 27 users responded to the survey, rating descriptions of 6 different prompts on a Likert scale, from strongly agree to strongly disagree.
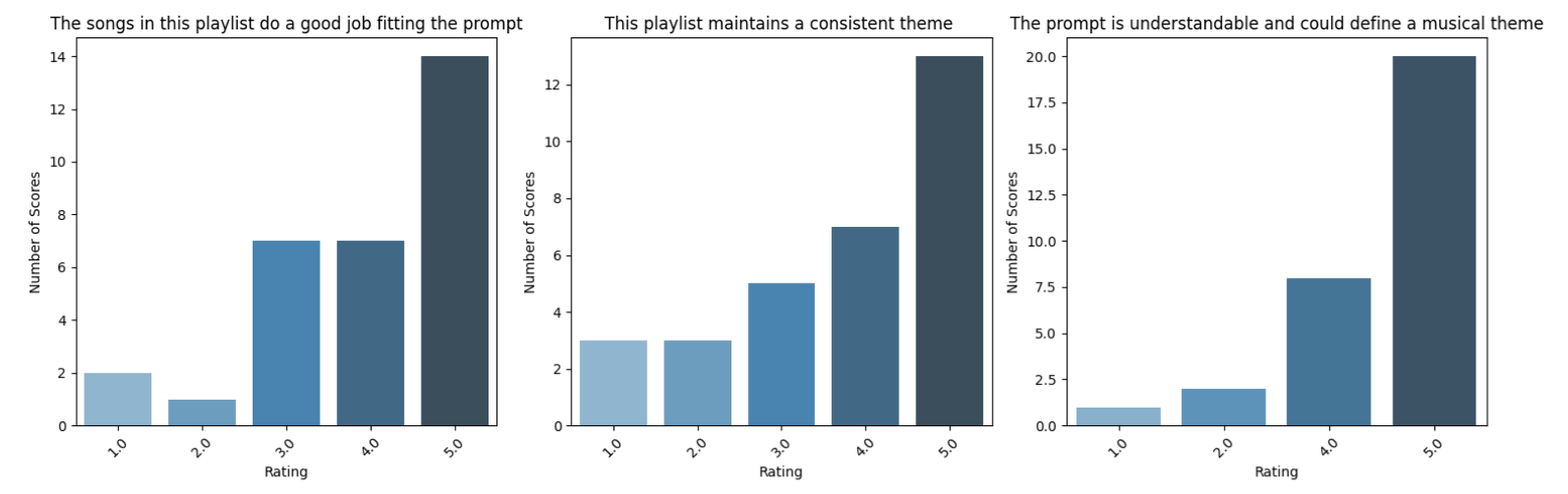
Visible in figure, the prompt descriptions were overwhelmingly rated as neutral or better, with a negative correlation between description rating and prompt opacity. Of course, the most fundamental result to evaluate was the end-to-end performance of our system – how users rate the playlists it curates. A survey to this end was designed with six prompts and their corresponding playlist recommendations. Each prompt-playlist pair was rated 1-5 on questions regarding fit, consistency, and prompt comprehensibility. Finally, participants were asked to select one of the six prompts and use it to generate a playlist with Spotify, to compare to the GorillaChow option.
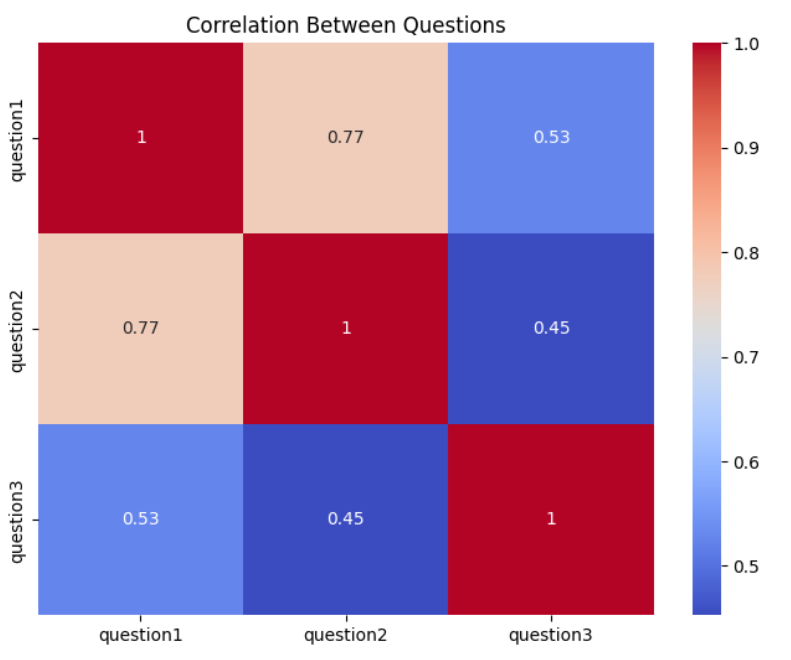
Participants generated 30 ratings of each question, with an average score of 3.97 / 5 for playlist fit, and 3.77 / 5 for playlist consistency. Users were also asked to rate the comprehensibility of each prompt, and we observed a moderate correlation of 0.77 between prompt comprehensibility and playlist consistency. Interestingly, prompt comprehensibility and playlist fit were not strongly correlated. Finally four participants generated playlists on Spotify and compared the results to the GorillaChow result. Three users preferred Spotify’s playlist, in two instances citing higher numbers of songs they were already familiar with, and in one a more consistent theme. One user was ambivalent toward the comparison, elaborating that GorillaChow created good variety while Spotify was samey.
Conclusion and Future Work
Because our application is limited in scope, an eventual increase in the dataset of recommendable songs would be a good next step. This would allow for more accurate recommendations and would make the application more useful. Without a large dataset, the recommendations can only be so good, that if we do not have a song to match the generated mood, the model will only spit out garbage. Another big thing that we would like to implement is to have more user feedback on the model's accuracy. This would allow us to improve the model in all aspects, from the prompt mood analysis to each song's given features.
Overall, however, we are pleased with the progress we have made so far, with the working demo and the results we have gathered from it. Notably, these results should be straightforward to reproduce, as the demo is available to anyone who wants to try it. Furthermore, all of the code used to create the demo is available on our Github, which is linked above. While the people who were surveyed did not think that our application was better than Spotify's, we are still happy with what we have created. With more data and more user feedback, we believe that our application could go toe to toe with Spotify's recommendations one day.